Bigtable: A Comprehensive Exploration of Google's Data Titan 🌐
An In-Depth Look at Google's Bigtable Data Storage System

Greetings, tech enthusiasts! Today, we embark on a profound exploration of one of Google's crowning achievements: Bigtable. Equipped with insights from Google's seminal research paper, this exploration will traverse the architectural intricacies, operational dynamics, and broader implications of this system. Let the deep dive commence! 🚀
Read the research paper here
1. Setting the Stage: The Data Explosion & Google's Predicament 🎇
The dawn of the 21st century heralded an era of data. With Google at the forefront of the digital revolution, its services began generating unfathomable amounts of data. Traditional databases, although reliable, groaned under the pressure, struggling with scalability and performance. Google's quest for a solution led to the inception of Bigtable.
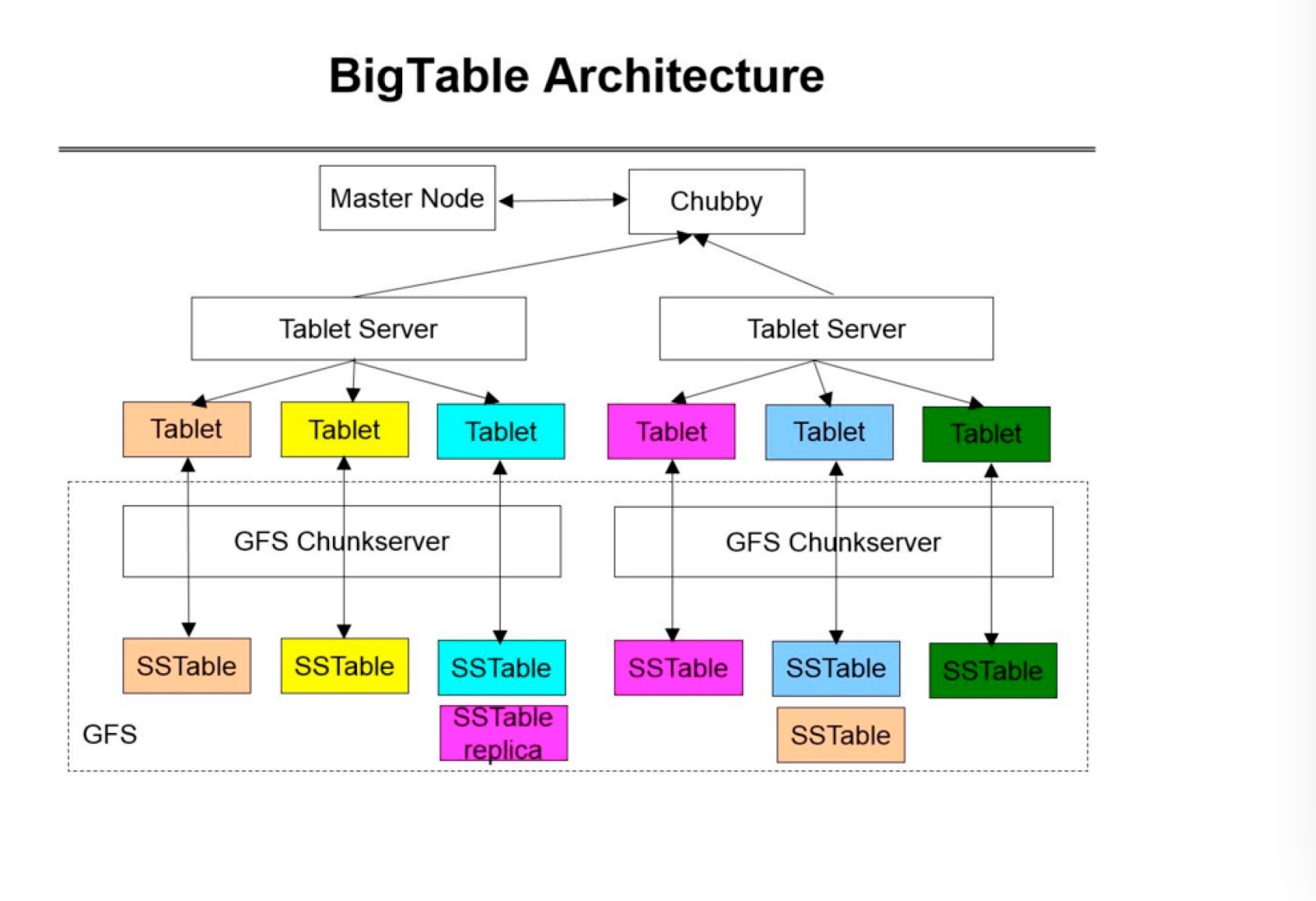
2. Bigtable Unpacked: Core Components & Design Philosophy 🧩
Data Model: Diverging from traditional norms, Bigtable's model is both dynamic and sparse, optimizing space and ensuring efficiency.
Rows & Columns: Rows have unique keys and are stored lexicographically, while columns, categorized into families, store multiple data versions timestamped for historical reference.
Tablet Storage: Tablets, or data chunks, are Bigtable's mechanism to ensure balanced data distribution and streamlined management.
Commit Logs: These act as the initial custodians of data, providing a layer of durability before data is transitioned to SSTables.
SSTables: The Storage Workhorse 🐎 SSTables, or Sorted String Tables, are an integral component of Bigtable's storage infrastructure. These are immutable, ordered data structures that store multiple versions of keys and values. Here's what makes SSTables special:
Efficiency: Being sorted, SSTables allow for rapid range queries and swift lookups.
Compaction: Over time, as data accumulates and older versions become obsolete, SSTables undergo a process called compaction. This consolidates data, discarding outdated versions and optimizing storage.
Merging: As data evolves, newer SSTables are created. Periodically, these tables are merged to ensure efficient storage and retrieval.
Immutability: SSTables are write-once structures. This immutability ensures consistent reads, reduces the potential for data corruption, and simplifies recovery in case of system failures.
Bloom Filters, Scan Cache, and Block Cache: The Performance Triad 🚀 To ensure swift data retrieval and optimized storage, Bigtable employs a trio of tools: Bloom Filters, Scan Cache, and Block Cache.
Bloom Filters: These probabilistic data structures allow Bigtable to quickly determine if a specific piece of data resides in an SSTable without scouring the entire table. They're a vital component in enhancing read performance and reducing unnecessary disk lookups.
Scan Cache: This is an in-memory cache that retains recently read key-value pairs, ensuring subsequent reads of the same data are significantly faster.
Block Cache: Another in-memory cache, the Block Cache retains portions of the SSTable, specifically blocks that have been recently read. This further accelerates data retrieval operations.

3. Advanced Mechanisms: Elevating Bigtable's Performance 🛠
While Bigtable's foundational architecture ensures stability and scalability, it's the advanced mechanisms working behind the scenes that truly elevate its performance. Let's explore some of these unsung heroes:
GFS Integration: Bigtable works hand in hand with the Google File System (GFS). SSTables are stored in GFS, which provides fault-tolerance, replication, and seamless data distribution. This collaboration ensures data durability even in the face of hardware failures.
MapReduce Compatibility: Bigtable is designed to work harmoniously with MapReduce, Google's processing framework. This allows developers to run complex computations on the data stored in Bigtable, making it more than just a storage system — it's a comprehensive data processing platform.
Consistent Backups: Bigtable's data backup mechanism ensures data safety. With incremental backups, only the changes since the last backup are stored. This not only ensures data integrity but also optimizes storage requirements.
Dynamic Load Balancing: As workloads change, Bigtable dynamically adjusts. It continually monitors workloads and redistributes tablets among servers to balance the load and optimize performance.
End-to-end Security: Data security is paramount. Bigtable integrates seamlessly with Google's security model, providing user authentication, strong access controls, and encrypted communications.
These advanced mechanisms ensure that Bigtable is not only efficient and scalable but also adaptable, secure, and primed for integrated data processing tasks.
4. Robustness in the Face of Adversity: Bigtable's Resilience Mechanisms 🛡
Machine Failures: Bigtable's design accounts for inevitable machine failures, with real-time monitoring and task reallocations ensuring uninterrupted service.
Load Imbalances: Bigtable's dynamic approach to tablet splitting and merging ensures consistent performance, preventing data bottlenecks.

5. Bigtable in Action: Real-World Deployments & Achievements 🌟
Google Earth: An astonishing 70TB of data, including intricate geographical details and high-res images, all managed seamlessly.
Google Analytics: A testament to Bigtable's prowess in data analytics, processing billions of URLs daily.
Google Search: Bigtable is the silent force ensuring that Google Search indexes and retrieves data in milliseconds.
6. Reflections: The Broader Implications of Bigtable's Design 🌌
Bigtable isn't just a technological marvel; it's a paradigm shift. Its design philosophy underscores the need for scalability, adaptability, and resilience in the age of big data. It exemplifies the fusion of innovative thought with real-world challenges, setting a precedent for future data management solutions.
7. Looking Ahead: The Future of Bigtable & Lessons for the Tech World 🚀
While Bigtable continues to be a cornerstone for Google, its implications extend beyond. The lessons from Bigtable's architecture and design are invaluable for the broader tech community. As data continues to grow, both in volume and complexity, systems inspired by Bigtable's principles will shape the future.
In wrapping up our journey, Bigtable stands as a beacon of human ingenuity and technological prowess. It's not just a system; it's a testament to what's possible when innovation meets necessity. Here's to the marvels of technology and the endless possibilities that await! 🌐🥂🔭




